This article is a summary for the paper by Jason Wang, Luis Perez, 2017.
Introduction and related work
Techniques for image data augmentation:
- cropping
- rotating
- flipping input images
- elastic deformation
- using GANs (generative adversarial networks) to generate images of different styles
- neural augmentation, which allows a neural net to learn augmentation that best improve the classifier
The key idea: take a small, curated corpus of structured data and augment it in a way that increases the performance of the model trained on it.
The motivation: specialized image and video classification tasks often have insufficient data. For example, in medical industry, data is protected due to privacy concerns. Small players in AI industry often lack access to large amounts of data.
datasets examined: 1) tiny-imagenet-200 data. It consists of 100k training, 10k validation, and 10k test images of dimensions 64x64x3. 500 images per class with 200 distinct classes; 2) MNIST. 60k handwritten digits in the training set, 10k in the test set in gray-scale with 10 classes. images of dimensions 28x28x1.
The authors restrict data to two classes and build constitutional neural net classifiers to correctly guess the class.
methods to reduce overfitting: 1) add a regularization term to the norm of the weights. 2) dropout 3) batch normalization 4) transfer learning. 5) data warping.
Methods
Approach 1: generate augmented data before training the classifier.
use traditional transformation techniques such as affine transformation
use GANs to generate images with style transformation
Approach 2: learn augmentation through a prepended neural net.
The training phase has two parts to the network: 1) the augmentation network takes in two images from the same class as input and returns a layer the same size as a single image. This layer is treated as an "augmented" image. 2) the augmented image as well as the original input images are then passed into the second network, the classification network.
The classification loss at the end of the network is a cross entropy loss on the sigmoids of the scores of classes. An addition loss is computed at the end of the augmentation network to regulate how similar the augmented image should be to the input image. The overall loss is a weighted sum of these two losses.
Three different approaches: 1) Content loss. 2) Style loss via gram matrix. 3) No loss is computed at this layer.
Datasets and Features
Three datasets and each dataset has two classes.
first dataset: taken from tiny-imagenet-200, 500 dog images, 500 cat images, image sizes are 64x64x3. training:validation = 4:1, RGB values are also normalized
second dataset: taken from tiny-imagenet- 200 except cats replaced with goldfish
third dataset: 2k images of 0's and 8's from MNIST, 1000 from each class. image sizes are 28x28x1, RGB values are also normalized.
Experiments
run 10 experiments on the image-net data. All experiments are run for 40 epochs at the learning rate of 0.0001 using Adam Optimization. The highest test accuracy at all the epochs is reported as the best score.
SmallNet has 3 convolution layers paired with a batch normalization and max pool layer followed by 2 fully connected layers. The output is a score matrix for the weights for each class.
Augmentation Network generates augmented image using CNN.
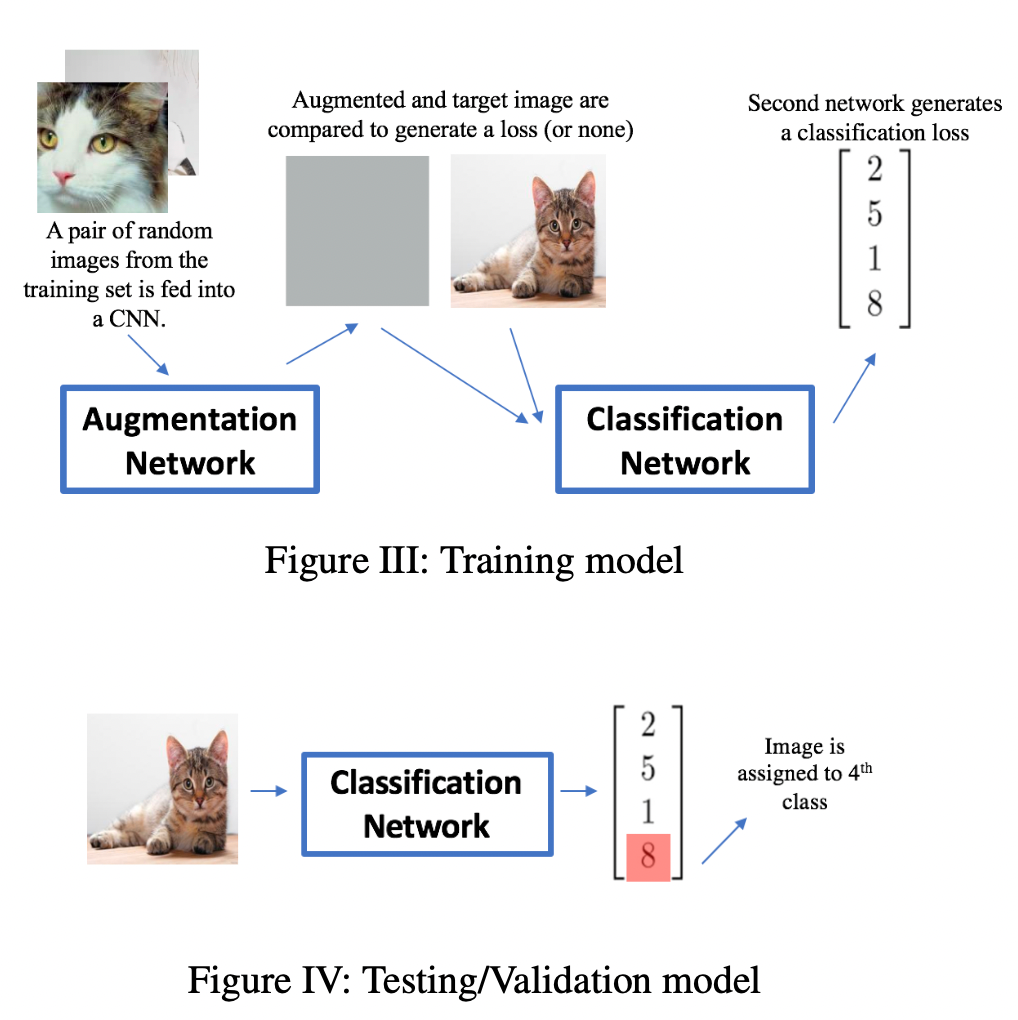
Loss is a weighted sum of classification loss and an augmentation loss (content loss, style loss).
Results
Neural augmentation has no effect on the MNIST dataset.
Questions:
- I did not quite understand the Results 5. CONTROL EXPERIMENT
The effect is a proxy to training a large 10-layer net on a single image without augmentation (pairing of different images).